Data Structures- Space and Time Complexity
Observing the time complexity of different algorithms




- Space and Time Complexity
- Constant O(1)
- Linear O(n)
- Quadratic O(n^2)
- Logarithmic O(logn)
- Exponential O(2^n)
- Hacks
- Record your findings when testing the time elapsed of the different algorithms.
- Do some basic research on the different types of sorting algorithms and their time complexity.
- Why is time and space complexity important when choosing an algorithm?
- Should you always use a constant time algorithm / Should you never use an exponential time algorithm? Explain?
- What are some general patterns that you noticed to determine each algorithm's time and space complexity?
- Time and Space Complexity analysis questions
Space and Time Complexity
Space complexity refers to the amount of memory used by an algorithm to complete its execution, as a function of the size of the input. The space complexity of an algorithm can be affected by various factors such as the size of the input data, the data structures used in the algorithm, the number and size of temporary variables, and the recursion depth. Time complexity refers to the amount of time required by an algorithm to run as the input size grows. It is usually measured in terms of the "Big O" notation, which describes the upper bound of an algorithm's time complexity.
Why do you think a programmer should care about space and time complexity?
- In a video game for example, the reaction time of a character has to do with time. Space has to do with how large an image may be for example. At times time and space can be related, a larger image may take a longer time to render. Without considering space time complexity of an algortithm can make it inefficient and take away from the program's purpose. In addition, not considering complexity can make the program an inconvinience for users.
Take a look at our lassen volcano example from the data compression tech talk. The first code block is the original image. In the second code block, change the baseWidth to rescale the image.
from IPython.display import Image, display
from pathlib import Path
# prepares a series of images
def image_data(path=Path("images/"), images=None): # path of static images is defaulted
for image in images:
# File to open
image['filename'] = path / image['file'] # file with path
return images
def image_display(images):
for image in images:
display(Image(filename=image['filename']))
if __name__ == "__main__":
lassen_volcano = image_data(images=[{'source': "Peter Carolin", 'label': "Lassen Volcano", 'file': "lassen-volcano.jpg"}])
image_display(lassen_volcano)

from IPython.display import HTML, display
from pathlib import Path
from PIL import Image as pilImage
from io import BytesIO
import base64
# prepares a series of images
def image_data(path=Path("images/"), images=None): # path of static images is defaulted
for image in images:
# File to open
image['filename'] = path / image['file'] # file with path
return images
def scale_image(img):
#baseWidth = 625
#baseWidth = 1250
#baseWidth = 2500
baseWidth = 5000 # see the effect of doubling or halfing the baseWidth
#baseWidth = 10000
#baseWidth = 20000
#baseWidth = 40000
scalePercent = (baseWidth/float(img.size[0]))
scaleHeight = int((float(img.size[1])*float(scalePercent)))
scale = (baseWidth, scaleHeight)
return img.resize(scale)
def image_to_base64(img, format):
with BytesIO() as buffer:
img.save(buffer, format)
return base64.b64encode(buffer.getvalue()).decode()
def image_management(image): # path of static images is defaulted
# Image open return PIL image object
img = pilImage.open(image['filename'])
# Python Image Library operations
image['format'] = img.format
image['mode'] = img.mode
image['size'] = img.size
image['width'], image['height'] = img.size
image['pixels'] = image['width'] * image['height']
# Scale the Image
img = scale_image(img)
image['pil'] = img
image['scaled_size'] = img.size
image['scaled_width'], image['scaled_height'] = img.size
image['scaled_pixels'] = image['scaled_width'] * image['scaled_height']
# Scaled HTML
image['html'] = '<img src="data:image/png;base64,%s">' % image_to_base64(image['pil'], image['format'])
if __name__ == "__main__":
# Use numpy to concatenate two arrays
images = image_data(images = [{'source': "Peter Carolin", 'label': "Lassen Volcano", 'file': "lassen-volcano.jpg"}])
# Display meta data, scaled view, and grey scale for each image
for image in images:
image_management(image)
print("---- meta data -----")
print(image['label'])
print(image['source'])
print(image['format'])
print(image['mode'])
print("Original size: ", image['size'], " pixels: ", f"{image['pixels']:,}")
print("Scaled size: ", image['scaled_size'], " pixels: ", f"{image['scaled_pixels']:,}")
print("-- original image --")
display(HTML(image['html']))

Do you think this is a time complexity or space complexity or both problem?
- I think it is both. In this case space and time is related in that a larger image takes a longer time to render, as it didn't show for a long time.
numbers = list(range(1000))
print(numbers[263])
ncaa_bb_ranks = {1:"Alabama",2:"Houston", 3:"Purdue", 4:"Kansas"}
#look up a value in a dictionary given a key
print(ncaa_bb_ranks[1])
Space
This function takes two number inputs and returns their sum. The function does not create any additional data structures or variables that are dependent on the input size, so its space complexity is constant, or O(1). Regardless of how large the input numbers are, the function will always require the same amount of memory to execute.
def sum(a, b):
return a + b
Time
An example of a linear time algorithm is traversing a list or an array. When the size of the list or array increases, the time taken to traverse it also increases linearly with the size. Hence, the time complexity of this operation is O(n), where n is the size of the list or array being traversed.
for i in numbers:
print(i)
Space
This function takes a list of elements arr as input and returns a new list with the elements in reverse order. The function creates a new list reversed_arr of the same size as arr to store the reversed elements. The size of reversed_arr depends on the size of the input arr, so the space complexity of this function is O(n). As the input size increases, the amount of memory required to execute the function also increases linearly.
def reverse_list(arr):
n = len(arr)
reversed_arr = [None] * n #create a list of None based on the length or arr
for i in range(n):
reversed_arr[n-i-1] = arr[i] #stores the value at the index of arr to the value at the index of reversed_arr starting at the beginning for arr and end for reversed_arr
return reversed_arr
print(numbers)
print(reverse_list(numbers))
Time
An example of a quadratic time algorithm is nested loops. When there are two nested loops that both iterate over the same collection, the time taken to complete the algorithm grows quadratically with the size of the collection. Hence, the time complexity of this operation is O(n^2), where n is the size of the collection being iterated over.
for i in numbers:
for j in numbers:
print(i,j)
Space
This function takes two matrices matrix1 and matrix2 as input and returns their product as a new matrix. The function creates a new matrix result with dimensions m by n to store the product of the input matrices. The size of result depends on the size of the input matrices, so the space complexity of this function is O(n^2). As the size of the input matrices increases, the amount of memory required to execute the function also increases quadratically.
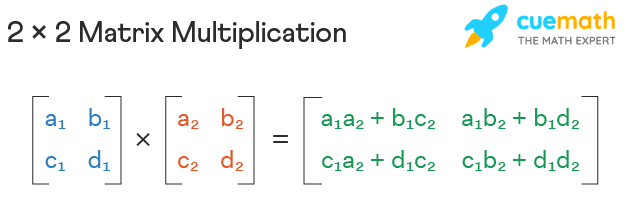
- Main take away is that a new matrix is created.
def multiply_matrices(matrix1, matrix2):
m = len(matrix1)
n = len(matrix2[0])
result = [[0] * n] * m #this creates the new matrix based on the size of matrix 1 and 2
for i in range(m):
for j in range(n):
for k in range(len(matrix2)):
result[i][j] += matrix1[i][k] * matrix2[k][j]
return result
print(multiply_matrices([[1,2],[3,4]], [[3,4],[1,2]]))
Time
An example of a log time algorithm is binary search. Binary search is an algorithm that searches for a specific element in a sorted list by repeatedly dividing the search interval in half. As a result, the time taken to complete the search grows logarithmically with the size of the list. Hence, the time complexity of this operation is O(log n), where n is the size of the list being searched.
def binary_search(arr, low, high, target):
while low <= high:
mid = (low + high) // 2 #integer division
if arr[mid] == target:
return mid
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
target = 263
result = binary_search(numbers, 0, len(numbers) - 1, target)
print(result)
Space
The same algorithm above has a O(logn) space complexity. The function takes an array arr, its lower and upper bounds low and high, and a target value target. The function searches for target within the bounds of arr by recursively dividing the search space in half until the target is found or the search space is empty. The function does not create any new data structures that depend on the size of arr. Instead, the function uses the call stack to keep track of the recursive calls. Since the maximum depth of the recursive calls is O(logn), where n is the size of arr, the space complexity of this function is O(logn). As the size of arr increases, the amount of memory required to execute the function grows logarithmically.
Time
An example of an O(2^n) algorithm is the recursive implementation of the Fibonacci sequence. The Fibonacci sequence is a series of numbers where each number is the sum of the two preceding ones, starting from 0 and 1. The recursive implementation of the Fibonacci sequence calculates each number by recursively calling itself with the two preceding numbers until it reaches the base case (i.e., the first or second number in the sequence). The algorithm takes O(2^n) time in the worst case because it has to calculate each number in the sequence by making two recursive calls.

def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
#print(fibonacci(5))
#print(fibonacci(10))
#print(fibonacci(20))
#print(fibonacci(30))
print(fibonacci(40))
Space
This function takes a set s as input and generates all possible subsets of s. The function does this by recursively generating the subsets of the set without the first element, and then adding the first element to each of those subsets to generate the subsets that include the first element. The function creates a new list for each recursive call that stores the subsets, and each element in the list is a new list that represents a subset. The number of subsets that can be generated from a set of size n is 2^n, so the space complexity of this function is O(2^n). As the size of the input set increases, the amount of memory required to execute the function grows exponentially.
def generate_subsets(s):
if not s:
return [[]]
subsets = generate_subsets(s[1:])
return [[s[0]] + subset for subset in subsets] + subsets
print(generate_subsets([1,2,3]))
#print(generate_subsets(numbers))
Using the time library, we are able to see the difference in time it takes to calculate the fibonacci function above.
- Based on what is known about the other time complexities, hypothesize the resulting elapsed time if the function is replaced. The difference between each time complexity depends on the type of multipler correlated with each. Exponential for example will be greater in time complexity than a multiplier of 5 because of the pattern of its growth.
import time
start_time = time.time()
print(fibonacci(34))
end_time = time.time()
total_time = end_time - start_time
print("Time taken:", total_time, "seconds")
start_time = time.time()
print(fibonacci(35))
end_time = time.time()
total_time = end_time - start_time
print("Time taken:", total_time, "seconds")
Hacks
- Record your findings when testing the time elapsed of the different algorithms.
- Although we will go more in depth later, time complexity is a key concept that relates to the different sorting algorithms. Do some basic research on the different types of sorting algorithms and their time complexity.
- Why is time and space complexity important when choosing an algorithm?
- Should you always use a constant time algorithm / Should you never use an exponential time algorithm? Explain?
- What are some general patterns that you noticed to determine each algorithm's time and space complexity?
Complete the Time and Space Complexity analysis questions linked below. Practice
import time
#constant time
def constant_time(n):
print("This is a constant time algorithm")
print("The result is:", n * 2)
#logarithmic time
def logarithmic_time(n):
print("This is a logarithmic time algorithm")
i = 1
while i < n:
print(i)
i *= 2
#linear time
def linear_time(n):
print("This is a linear time algorithm")
for i in range(n):
print(i)
#quadratic time
def quadratic_time(n):
print("This is a quadratic time algorithm")
for i in range(n):
for j in range(n):
print(i, j)
#exponential time
def exponential_time(n):
print("This is an exponential time algorithm")
if n <= 1:
return n
else:
return exponential_time(n-1) + exponential_time(n-2)
n = 1
start_time = time.time()
constant_time(n)
end_time = time.time()
print("Time taken for constant time:", end_time - start_time, "seconds")
start_time = time.time()
logarithmic_time(n)
end_time = time.time()
print("Time taken for logarithmic time:", end_time - start_time, "seconds")
start_time = time.time()
linear_time(n)
end_time = time.time()
print("Time taken for linear time:", end_time - start_time, "seconds")
start_time = time.time()
quadratic_time(n)
end_time = time.time()
print("Time taken for quadratic time:", end_time - start_time, "seconds")
start_time = time.time()
exponential_time(n)
end_time = time.time()
print("Time taken for exponential time:", end_time - start_time, "seconds")
n = 1: Time taken for constant time: 0.0013301372528076172 seconds Time taken for logarithmic time: 0.00034618377685546875 seconds Time taken for linear time: 0.0004546642303466797 seconds Time taken for quadratic time: 0.00058746337890625 seconds Time taken for exponential time: 0.00028896331787109375 seconds
n = 10: Time taken for constant time: 0.0019936561584472656 seconds Time taken for logarithmic time: 0.0006468296051025391 seconds Time taken for linear time: 0.0027747154235839844 seconds Time taken for quadratic time: 0.061913490295410156 seconds Time taken for exponential time: 0.05074191093444824 seconds
- Log is fastest
- Exponential time increases as space increases
- Quadratics take longer than linear
Bubble Sort:
- Repeatedly swaps adjacent elements if they are in the wrong order until the list is sorted. The time complexity of bubble sort is O(n^2) Insertion Sort:
- Compared each element in turn with the ones before it and inserting it into the correct position in the sorted sequence. The time complexity of insertion sort is O(n^2). Selection Sort:
- This algorithm works by selecting the smallest element from the unsorted portion of the list and swapping it with the first element in the unsorted portion until the list is sorted. The time complexity of selection sort is also O(n^2). Binary Sort:
- Olog(n) because binary search works by comparing given number to median of data set. Also as the dataset grows, the time complexity grows logarithmically
Why is time and space complexity important when choosing an algorithm?
- Time and space complexity directly impact the efficiency of an algorithm. The more efficient an algorithm is, the faster and less memory it consumes
- If an algorithm has high time and large space complexity, it will become impractical for larger data sets.
Should you always use a constant time algorithm / Should you never use an exponential time algorithm? Explain?
This is not necessarily true in all cases. Constant time algorithms require less time to run and are eficient however not all problems can be solved with constant algorithms. Some issues may require exponential algorithms to solve it.
What are some general patterns that you noticed to determine each algorithm's time and space complexity?
- Counting the number of basic operations: The time complexity of an algorithm is proportional to the number of basic operations it performs, like arithmetic operations, assignments, comparisons
- Examining nested loops: Nested loops are a common cause of high time complexity. If an algorithm contains nested loops, the time complexity is often proportional to the number of iterations
- Recursive calls: If an algorithm makes a large number of recursive calls, the time complexity may be high.
- Data structures: The space complexity of an algorithm often depends on the size of the data structures it uses.
- If an algorithm contains many conditional statements, the time complexity may be higher.
- What is the time, and space complexity of the following code:
- O(N * M) time, O(1) space
- O(N + M) time, O(N + M) space
- O(N + M) time, O(1) space
- O(N * M) time, O(N + M) space
I choose number 3 because there are two independent variables N and M, and the variable sizes dont depend on the size of the input. So must be (N+M) and (1)
int a = 0, b = 0;
for (i = 0; i < N; i++) {
a = a + rand();
}
for (j = 0; j < M; j++) {
b = b + rand();
}
- What is the time complexity of the following code:
- O(N)
- O(N*log(N))
- O(N * Sqrt(N))
- O(N*N)
I chose option 4 because there is a for loop within one loop, so O^2.
int a = 0;
for (i = 0; i < N; i++) {
for (j = N; j > i; j--) {
a = a + i + j;
}
}
- What is the time complexity of the following code:
- O(n)
- O(N log N)
- O(n^2)
- O(n^2Logn) I chose option 2 O(nlogn) because j doubles until it is less than or equal to n, so there is logarithmic correlation
- What does it mean when we say that an algorithm X is asymptotically more efficient than Y?
- X will always be a better choice for small inputs
- X will always be a better choice for large inputs
- Y will always be a better choice for small inputs
- X will always be a better choice for all inputs
I chose option 2, because aymptotic means growth of algorithm increases in terms of the input.
int a = 0, i = N;
while (i > 0) {
a += i;
i /= 2;
}
- What is the time complexity of the following code:
- O(N)
- O(Sqrt(N))
- O(N / 2)
- O(log N)
I chose option 4 because it outputs the smallest x, x = log(N)
- Which of the following best describes the useful criterion for comparing the efficiency of algorithms?
- Time
- Memory
- Both of the above
- None of the above
I chose both of the above, because both of these factors affect the efficiency of an algorithm
- How is time complexity measured?
- By counting the number of algorithms in an algorithm.
- By counting the number of primitive operations performed by the algorithm on a given - input size.
- By counting the size of data input to the algorithm.
- None of the above
I chose option 2, the number of primitive operations directly affect the complexity
for(var i=0;i<n;i++)
i*=k
- What will be the time complexity of the following code?
- O(n)
- O(k)
- O(logkn)
- O(lognk)
I chose option 3 because as it loops for k^n-1 times, taking the log it becomes logk(n)
int value = 0;
for(int i=0;i<n;i++)
for(int j=0;j<i;j++)
value += 1;
- What will be the time complexity of the following code?
- n
- (n+1)
- n(n-1)
- n(n+1)
I chose option 3 because there is a for loop within another for loop.
- Algorithm A and B have a worst-case running time of O(n) and O(logn), respectively. Therefore, algorithm B always runs faster than algorithm A?
- True
- False
I chose the option False because the O notation provides asymptotic comparison. SO there are situations where algorithm A may run faster than B.